https://www.datamanim.com/dataset/03_dataq/typeone.html#id6
작업 1유형 — DataManim
Question 각 비디오는 10분 간격으로 구독자수, 좋아요, 싫어요수, 댓글수가 수집된것으로 알려졌다. 공범 EP1의 비디오정보 데이터중 수집간격이 5분 이하, 20분이상인 데이터 구간( 해당 시점 전,후
www.datamanim.com
Question
price_range 의 각 value를 그룹핑하여 각 그룹의 n_cores 의 빈도가 가장높은 value와 그 빈도수를 구하여라
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/Datamanim/datarepo/main/mobile/train.csv")
df.head()
data = df[['price_range','n_cores']].groupby(['price_range','n_cores']).size()
data
df[['price_range','n_cores']].groupby(['price_range','n_cores']).size().sort_values(0)
pandas.Series.sort_values()
parameters; 축 : 기본값이 0, 직접 정렬을 위한 축
DataFrame.sort_values와의 호환성을 위해 'index'값이 허용됨
df[['price_range','n_cores']].groupby(['price_range','n_cores']).size().sort_values(0).groupby(level=0).head()
level은 index의 깊이를 의미하며 가장 왼쪽에서부터 0에서부터 1씩 증가
answer = df[['price_range','n_cores']].groupby(['price_range','n_cores']).size().sort_values(0).groupby(level=0).tail(1)
answer
Question
price_range 값이 3인 그룹에서 상관관계가 2번째로 높은 두 컬럼과 그 상관계수를 구하여라
df.loc[df['price_range']==3].corr()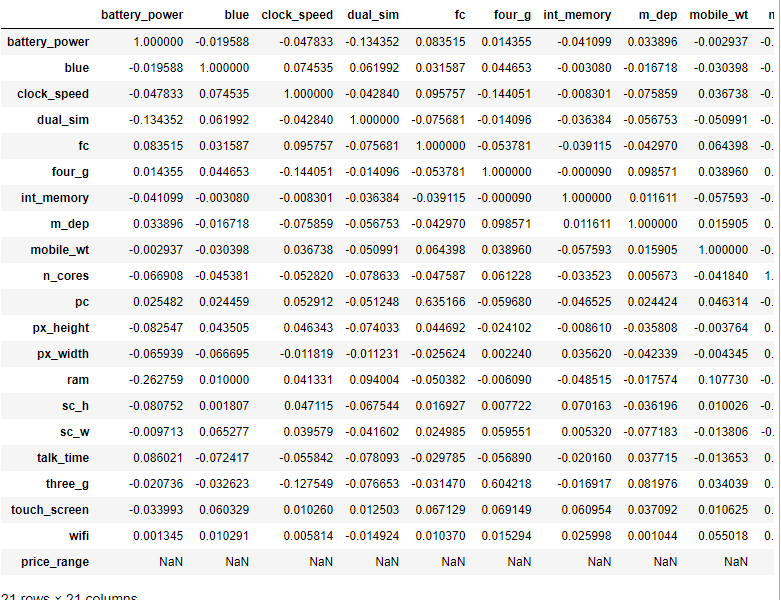
df.loc[df['price_range']==3].corr().unstack()
cordf = df.loc[df['price_range']==3].corr().unstack().sort_values(ascending=False)
cordf
cordf = df.loc[df['price_range']==3].corr().unstack().sort_values(ascending=False)
answer = cordf.loc[cordf!=1].reset_index().iloc[1]
print(answer)
'빅데이터분석기사 > 작업 1유형' 카테고리의 다른 글
| 수질 음용성 여부 데이터 (0) | 2022.08.15 |
|---|---|
| 비행 탑승 경험 만족도 데이터 (0) | 2022.08.15 |
| 자동차 보험가입 예측데이터 (0) | 2022.08.15 |
| 성인 건강검진 데이터 (0) | 2022.08.15 |
| 서비스 이탈예측 데이터 (0) | 2022.08.15 |